
BigQueryでdbt macrosを触ってみる
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
Google Cloudデータエンジニアのはんざわです。
最近はdbtを触る機会が多く、前回と前々回に続きdbtのブログになります。
今回のブログでは、dbt macrosを触ってみたいと思います。
dbt macrosとは?
dbtでは、Pythonのテンプレートエンジンである Jinja とJinjaの機能である macros を使って、SQLを柔軟に記述することができます。
JinjaはSQLと組み合わせることでSQL単体では実現できないことができるようになります。
以前に投稿したブログで使用していた{{ source( ... ) }}もJinjaの表記になります。
macrosは他のプログラミング言語の「関数」のように再利用可能なクエリを定義し、呼び出すことができる機能です。
デフォルトでは、dbtプロジェクトのmacrosディレクトリで再利用したいクエリを定義します。
検証内容
今回の検証では、次の2つのdbt macrosを作成し、モデルで呼び出してみたいと思います。
- 文字列の接尾語に
_Hello Worldを加える - 指定したテーブルの特定のキーのカウントを取得する
前提
- 実行環境は以前の投稿したブログと同じ
dbt init dbt_macrosで新規のdbtプロジェクトを作成済み- BigQueryで
dbt_macrosと名付けたデータセットをUSリージョンに作成し、dbtプロジェクトの出力先データセットに指定する
検証の準備
さっそく検証の準備を進めていきたいと思います。
ディレクトリ構成
最終的なディレクトリ構成は以下のようになりました。
% tree macros_test
macros_test
├── macros
│ ├── add_hello_world.sql
│ └── get_key_counts.sql
├── models
│ └── macros_test
│ ├── src_tables.yml
│ ├── test1.sql
│ └── test2.sql
// 省略
18 directories, 20 files
それぞれのファイルの詳細は次の通りです。
ソース(source)
以下のようにソースを定義しています。詳細は前回のブログを確認してください。
version: 1
sources:
- name: samples_tables
database: bigquery-public-data
schema: samples
tables:
- name: shakespeare
マクロ(macros)
dbt macrosは、以下のようなフォーマットで定義します。
{% macro function_name(*args, **kwargs) %}
{% endmacro %}
最初に{% macro function_name(*args, **kwargs) %}で関数名と引数を定義し、最後に{% endmacro %}で締めます。
関数で定義した引数は{{ args }}で呼び出すことができます。
詳細は以下のドキュメントを参考にしてください。
さっそく前述した2つのマクロを作成します。
- 文字列の接尾語に
_Hello Worldを加える
関数名をadd_hello_worldとし、引数にinput_textを渡しています。
CONCATで引数のinput_textと_Hello Worldを連結するだけのシンプルなマクロです。
{% macro add_hello_world(input_text) %}
(CONCAT({{ input_text }}, '_Hello World') )
{% endmacro %}
- 指定したテーブルの特定のキーのカウントを取得する
関数名をget_key_countsとし、引数にinput_tableとinput_keyを渡しています。
input_tableでテーブルを指定し、input_keyでグループ化してそれぞれの要素をカウントするマクロです。
{% macro get_key_counts(input_table, input_key) %}
SELECT
{{ input_key }},
COUNT(*) AS cnt
FROM
{{ input_table }}
GROUP BY {{ input_key }}
{% endmacro %}
最後にモデルでこれらのマクロを呼び出してみます。
モデル(models)
まずはadd_hello_worldのマクロを呼び出してみます。
ファイル名をtest1.sqlとして、引数のinput_textにソースで定義したテーブルのwordカラムを指定しています。
また、materializedをtableに指定しているため、モデルを実行すると事前に指定したデータセットにテーブルが作成されます。
このモデルを見て分かる通り、add_hello_worldは文字列を結合処理するだけのものであるため、SELECT句でマクロを呼び出しています。
{{
config(
materialized='table'
)
}}
SELECT
word,
{{ add_hello_world('word') }} AS word_hello_world
FROM
{{ source('samples_tables', 'shakespeare') }}
次にget_key_countsのマクロを呼び出してみます。
ファイル名をtest2.sqlとして、引数のinput_tableにソースで定義したテーブルを与え、input_keyにwordカラムを指定しています。
先ほどのモデルとは違い、get_key_countsはマクロの中で処理が完結しているため、引数を与えるだけのモデルとなっています。
このように一部の処理をマクロ化して再利用することも可能ですし、まとまった処理をマクロ化することも可能です。
{{
config(
materialized='table'
)
}}
{{ get_key_counts(source('samples_tables', 'shakespeare'), 'word') }}
動かしてみる
さっそくdbt runで動かしてみます。
% dbt run
16:41:43 Running with dbt=1.8.3
16:41:44 Registered adapter: bigquery=1.8.2
16:41:44 Found 2 models, 1 source, 473 macros
16:41:44
16:41:46 Concurrency: 1 threads (target='dev')
16:41:46
16:41:46 1 of 2 START sql table model dbt_macros.test1 .................................. [RUN]
16:41:50 1 of 2 OK created sql table model dbt_macros.test1 ............................. [CREATE TABLE (164.7k rows, 1.3 MiB processed) in 3.99s]
16:41:50 2 of 2 START sql table model dbt_macros.test2 .................................. [RUN]
16:41:54 2 of 2 OK created sql table model dbt_macros.test2 ............................. [CREATE TABLE (32.8k rows, 1.3 MiB processed) in 3.99s]
16:41:54
16:41:54 Finished running 2 table models in 0 hours 0 minutes and 9.86 seconds (9.86s).
16:41:54
16:41:54 Completed successfully
16:41:54
16:41:54 Done. PASS=2 WARN=0 ERROR=0 SKIP=0 TOTAL=2
正常に成功しました!
BigQueryにテーブルが作成されているか確認してみます。

上記のキャプチャのようにdbt_macrosのデータセット配下にtest1とtest2のテーブルが作成されていました。
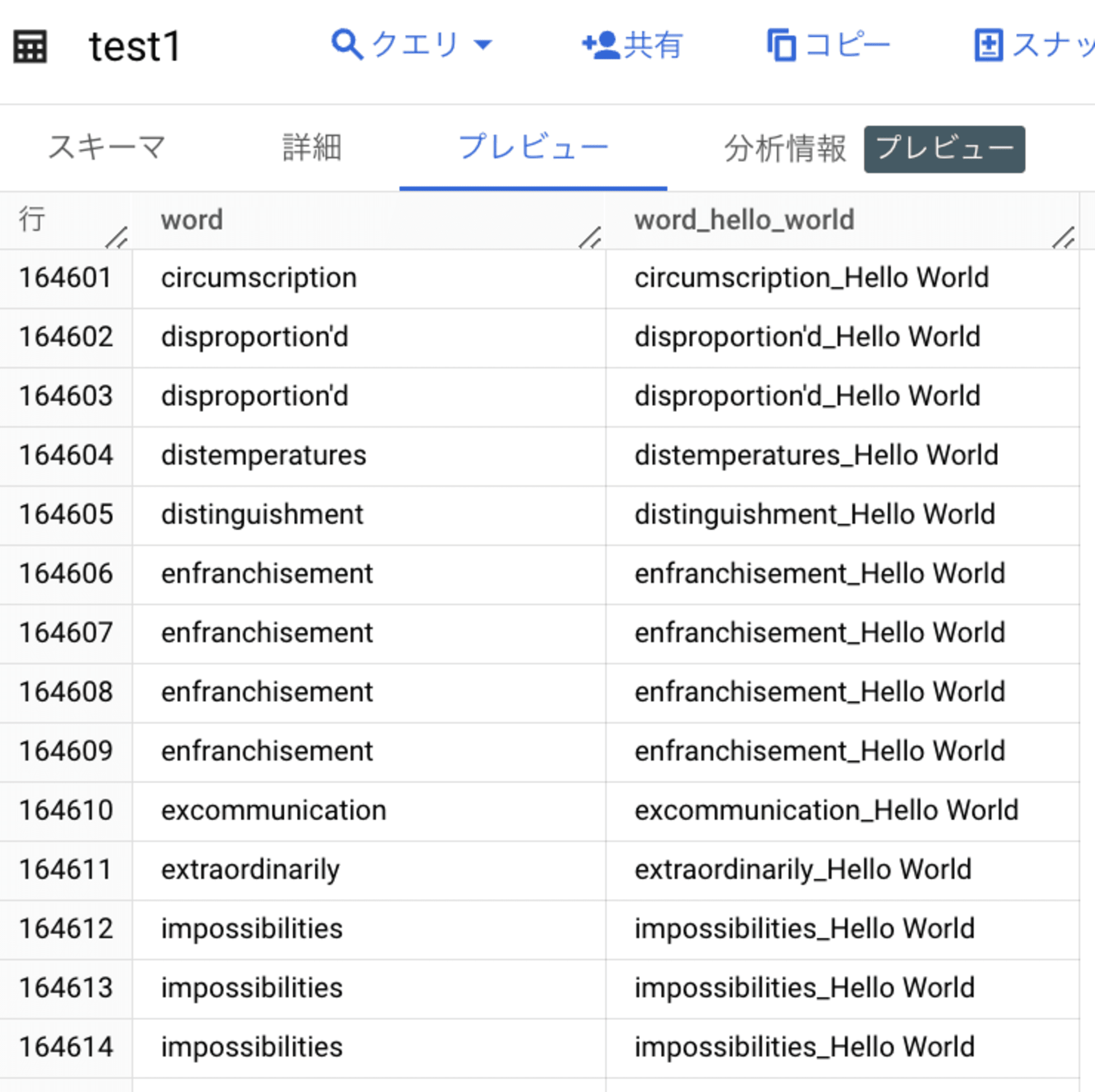
test1のテーブルを確認すると想定通りに接尾語に_Hello Worldが付いていました。
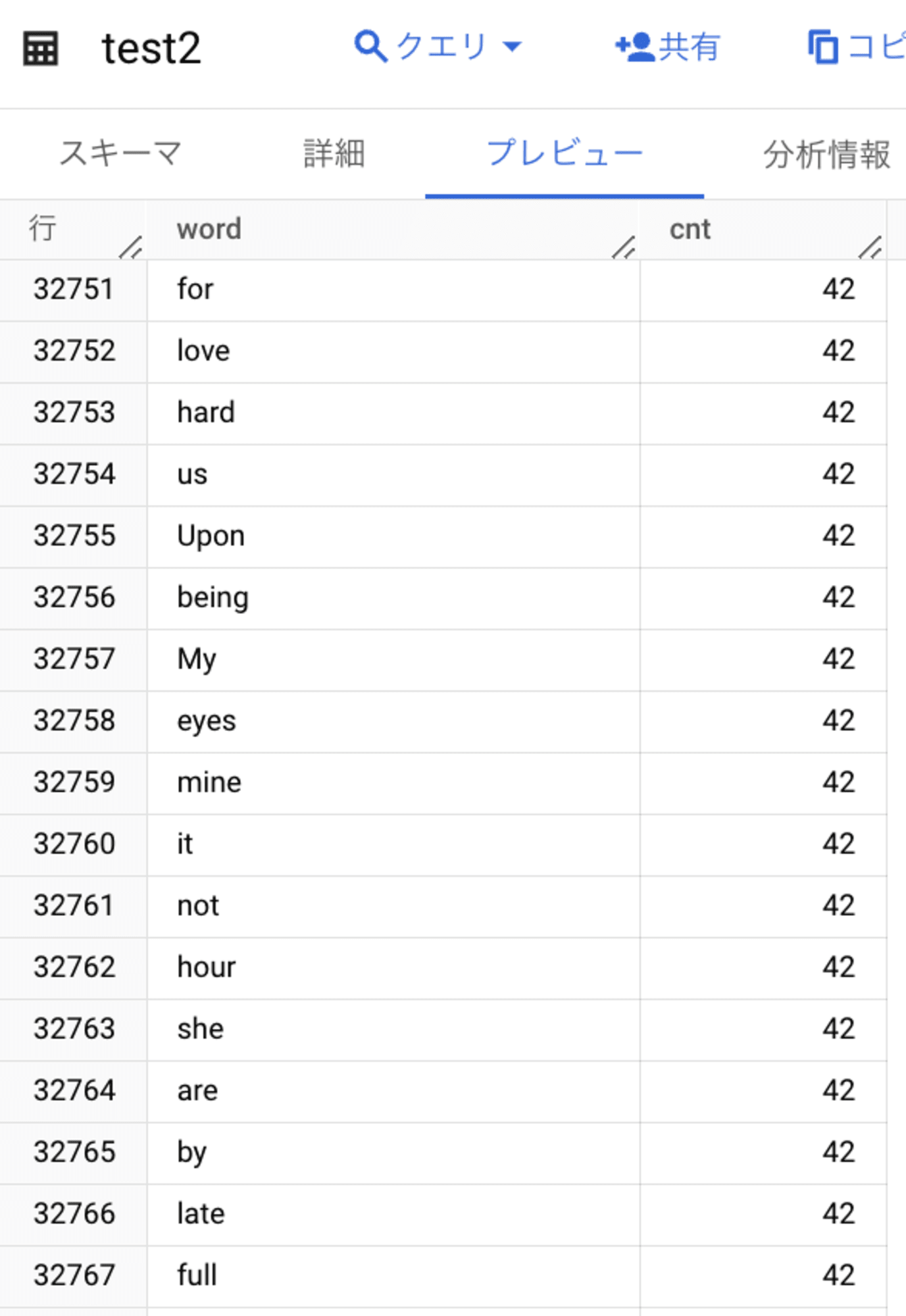
test2のテーブルも想定通りに各要素がカウントされていました。
最後にBigQueryのジョブ履歴でdbtから発行されたクエリの履歴を確認してみます。
以下の2つのクエリがtest1とtest2のテーブルを作成したクエリになります。
これらを見て分かるようにマクロで定義したクエリがモデルで展開され、新しいクエリが生成されています。
/* {"app": "dbt", "dbt_version": "1.8.3", "profile_name": "macros_test", "target_name": "dev", "node_id": "model.macros_test.test1"} */
create or replace table `PROJECT_ID`.`dbt_macros`.`test1`
OPTIONS()
as (
SELECT
word,
(CONCAT(word, '_Hello World') )
AS word_hello_world
FROM
`bigquery-public-data`.`samples`.`shakespeare`
);
/* {"app": "dbt", "dbt_version": "1.8.3", "profile_name": "macros_test", "target_name": "dev", "node_id": "model.macros_test.test2"} */
create or replace table `PROJECT_ID`.`dbt_macros`.`test2`
OPTIONS()
as (
SELECT
word,
COUNT(*) AS cnt
FROM
`bigquery-public-data`.`samples`.`shakespeare`
GROUP BY word
);
まとめ
今回はdbt macrosを簡単に紹介しました。
dbt macrosを導入することでクエリの再利用性が向上し、それに伴って保守性の向上やテストの効率化など様々なメリットが生まれます。
また、本ブログでは紹介できませんでしたが、IF文を使った条件分岐やFOR文を使ったループ処理も可能ですので、是非活用してみてください。










